
Intellegenter Fahren: LLMs Verkehrsregeln beibringen, um autonome Fahrzeuge zu unterstützen
Dieses Projekt untersucht die Fähigkeit großer Sprachmodelle (LLMs), Verkehrsregeln effektiv zu verstehen und anzuwenden. Durch die Verwendung von theoretischen Führerscheinprüfungsfragen als Testsets bewerten wir, inwieweit LLMs eine theoretische Fahrprüfung erfolgreich bestehen können. Über das bloße Beantworten der Fragen hinaus integriert das Projekt offizielle gesetzliche Texte zu Verkehrsregeln in die LLMs. Diese Erweiterung ermöglicht es den Modellen nicht nur, korrekte Antworten zu geben, sondern auch relevante gesetzliche Verweise anzuführen und die Begründung hinter ihren Antworten zu erklären. Das übergeordnete Ziel ist es, zu bewerten, wie gut LLMs Verkehrsrecht interpretieren, anwenden und begründen können, um so zu ihrem potenziellen Einsatz in der juristischen Argumentation und in autonomen Fahrsystemen beizutragen.
Juristischer Textparser
Ein kürzlich auf der ESSV 2025 vorgestellter Parser zur Extraktion wichtiger Informationen aus Rechtstexten hat sich bei der Bearbeitung von StVO-Dokumenten als äußerst effizient erwiesen.
Dieser Parser nutzt die inhärente Struktur des Rechtstextes, in der Informationen klar in mehrere Ebenen wie Kapitel, Absätze, Sätze usw. segmentiert und stark miteinander verknüpft sind. Mithilfe dieses Informationsparsers wird ein Wissensgraph erstellt, der den ursprünglichen Inhalt zuverlässig rekonstruiert und als solide Grundlage für weitere Recherchen dienen kann.
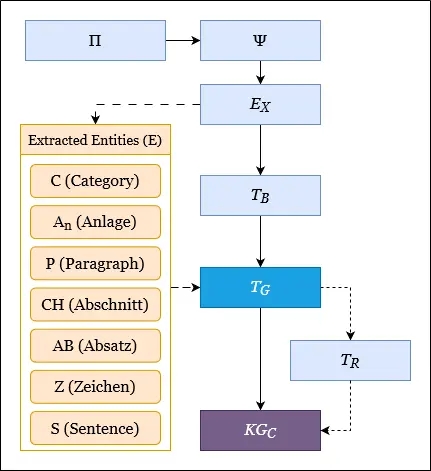
Parser-Workflow:
- Musterabgleich (Ψ): Erkennt relevanten Text.
- Entitätsextraktion (EX): Extrahiert juristische Entitäten.
- Baumaufbau (TB): Erstellt einen hierarchischen Baum.
- Entitätstagging (TG): Kennzeichnet Baumknoten mit ihren Entitätstypen.
- Übersetzung (TR) (optional): Übersetzung vom Deutschen ins Englische.
- KG-Konstruktion (KGC): Definiert Kanten basierend auf Zitaten und Hierarchien.
Project Team






